Часто, при разработке программного обеспечения на каком–нибудь языке, бывает необходимо интегрировать библиотеки, которые были написанные на других языках программирования по следующим двум причинам:
В данном случае получаем программу, которая собрана из кусков на различных языках и каждый из этих специализированных кусков написан на наиболее подходящем для решения данной проблемы языке. Такие части программы взаимодействуют между собой, передавая данные и выполняя расчет.
В Objective CAML существует механизм взаимодействия с языком C. Из кода Objective CAML можно вызвать функцию на C, передать аргументы и получить результат расчета. Обратное так же возможно: программа на C может вызвать расчет на Objective CAML и затем продолжить обрабатывать полученный результат.
Выбор языка C оправдан следующими причинами:
В последнем случае C выступает в роли эсперанто языков программирования.
Однако, взаимодействие между Objective CAML и C создает определенные трудности, которые представлены ниже:
Программы на Objective CAML наследуют надежность статической типизации и автоматическое управление памятью. Корректное использование библиотек на C или взаимодействие посредством C не должно подвергнуть риску эту надежность. Поэтому, для гармоничного взаимодействия обоих языков, необходимо следовать четким правилам.
В данной главе, мы рассмотрим средства, входящие в дистрибутив Objective CAML, для взаимодействия с C, которые позволят создать исполняемые файлы, состоящих из частей на обоих языках программирования. Эти средства предоставляют функции, при помощи которых можно перевести значение из одного языка в другой, надежно выделить память в C, используя кучу Objective CAML и GC, а так же возбудить исключения Objective CAML в C.
В первой части главы мы рассмотрим использование C функции в Objective CAML, как создать исполнимый файл и интерактивную среду, которые содержат эту функцию. Во второй части мы изучим каким образом значения Objective CAML представлены в C. В следующей части уточняется как создавать и менять значения Objective CAML в C. В ней так же рассматриваются проблемы, возникающие при выделении памяти в C в “присутствии” GC Objective CAML, а так же способы надежного выделения памяти в C. В пятой главе описано управление исключениями, как они возбуждаются и отлавливаются в зависимости от места остановки расчета. В последней части мы рассмотрим как использовать код Objective CAML в C.
Замечание
Для изучения следующего материала, необходимы знания языка C. Так же,
желательно прочесть главу 8, для четкого понимания проблем
связанных с автоматической сборкой памяти.
Передача информации между Objective CAML и C осуществляется созданием исполняемого файла (или интерактивной среды), состоящей из двух частей, которые могут быть скомпилированы раздельно. И тогда, до создания исполнимого файла, компоновщик должен установить связь между именами Objective CAML и C. Для этого программа на Objective CAML должна содержать внешние декларации.
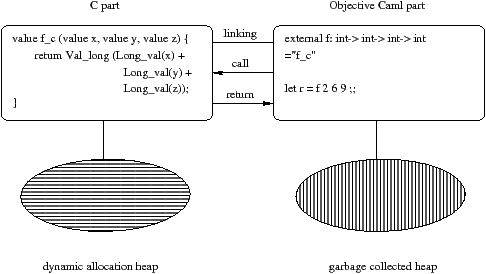
На рисунке 11.1 изображена программа, состоящая из одного куска на C и другого на Objective CAML.
Можно представить каждую часть, как содержащую код, инструкции, соответствующие определению функций и вычислению выражений Objective CAML, а так же зоны динамического выделения памяти. Применение функции f к трем целым числам Objective CAML провоцирует вычисление функции f_c на C. Тело функции переводит целые числа Objective CAML в целые числа C, вычисляет сумму и затем возвращает результат переведенный в целое число Objective CAML.
Далее будут представлены первичные элементы взаимодействия Objective CAML и C: внешние декларации, ограничения накладываемые на C функции, которые можно вызвать в Objective CAML и опции редактора связей. Затем мы приведем пример использования ввода/вывода.
Внешние декларации функций в Objective CAML необходимы для установления связи между декларацией функции C и именем в Objective CAML, а так же для указания типа функции.
Синтаксис декларации следующий:
Синтаксис 10cmexternal caml_name : type = "C_name"
Эта запись означает, что вызов функции caml_name в Objective CAML спровоцирует вызов функции C C_name с соответствующими аргументами. В примере на изображении 11.1 декларируется функция f, вызов которой соответствует выполнению функции f_c.
Можно объявить функцию, как внешнюю в интерфейсе (т.е. в файле .mli), либо явно указывая на то, что она внешняя, либо как обычное значение:
Синтаксис 10cm
external caml_name : type = "C_name"
val caml_name : type
Во втором случае, вызов C функции проходит через общий механизм функций Objective CAML. Подобный подход менее эффективен, но он скрывает реализацию функции как C функции.
Число аргументов C функций, вызываемых в Objective CAML, должно быть одинаковым с внешним объявлением функции. Тип значений Objective CAML в C: value. Так как представление этих значений является однородным (??), то их можно представить одним единственным типом C. На стр. ?? мы познакомимся со средствами перевода значений и продемонстрируем функцию экспорта значений Objective CAML.
Функция на изображении 11.1 соответствует приведенным ограничениям. Функция f_c связана с функцией Objective CAML, тип которой int -> int -> int -> int и является функцией с тремя аргументами и результатом типа value.
Интерпретатор байт–кода по разному вычисляет вызовы функции в зависимости от числа аргументов1. Если число аргументов меньше или равно пяти, то они помещаются в стек. Если же число аргументов больше пяти, то в C функцию передается вектор, содержащий все входные аргументы и затем число аргументов. Необходимо разделять оба случая, так как C функция может быть вызвана интерпретатором байт–кода. С другой стороны, нативный компилятор всегда вызывает внешнюю функцию передавая ей напрямую все входные аргументы.
В данном случае нужно написать две функции, одну для байт–код интерпретатора, а другую для нативного. Синтаксис внешних деклараций позволяет использовать одну декларацию для обеих функций C:
Синтаксис 10cm
external caml_name : type = "C_name_bytecode" "C_name_native"
У функции C_name_bytecode два аргумента: вектор значений с типом value (C указатель на тип *value) и целое число, которое указывает размер вектора.
Следующая программа на C определяет две разные функции для сложения шести целых чисел: plus_native для нативного кода и plus_bytecode для вызова из байт–код интерпретатора. Необходимо указать файл mlvalues.h, в котором содержится определение C типов значений Objective CAML и макросы преобразования.
Программа на Objective CAML exOCAML.ml вызывает обе C функции.
Теперь скомпилируем обе программы двумя компиляторами Objective CAML и компилятором C, который назовем cc.
Для того, чтобы не переписывать два раза функцию, простейшим решением может быть использование нативной функции в теле функции для байт–код интерпретатора, как указано в примере:
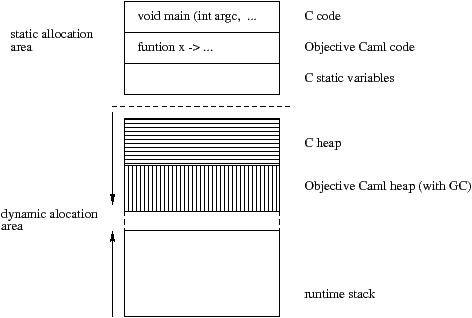
Из скомпилированных файлов на Objective CAML и C, компоновщик создает исполняемый файл. Результат, полученный нативным компилятором, изображен на рисунке 11.2.
Инструкции программ на Objective CAML и C размещены в статической зоне памяти. В динамической зоне находится стек выполнения (где располагаются текущие вызовы) и кучи Objective CAML и C.
Функции на C, которые могут быть вызваны в программе и использующие лишь стандартные библиотеки, содержатся в execution библиотеке (см. рис. 6.1 на стр. ??). То есть нет необходимости что–либо дополнительно указывать. Однако, в случае если мы используем библиотеки Graphics, Num и Str необходимо указать компоновщику связей библиотеки, соответствующие приведенным модулям. Для этого существует опция компилятора -custom. Тот же принцип применяется и к функциям C, которые мы желаем использовать: необходимо указать объектный файл содержащий эти функции при редактировании связей компоновщиком. Мы продемонстрируем это на примере.
Необходимо различать компиляцию нативного компилятора, байт–код компилятор и создание интерактивной среды. Опции для различных типов компиляций описаны в главе 6.
Вернемся к изображению 11.1, чтобы проиллюстрировать три режима компиляции. Для этого переименуем файл Objective CAML в progocaml.ml. В этом файле вызывается внешняя функция из C файла progC.c, который в свою очередь использует C библиотеку libC. После того, как эти файлы скомпилированы независимо друг от друга, редакция связей осуществляется следующими командами:
После этого получим два исполняемых файла: vbc.exe для байт–код версии и для нативной vn.exe.
Мы можем обогатить runtime библиотеку, включив в нее новые C функции. Для этого существуют следующие команды:
Теперь можно создать байт–код файл vbcnam.exe используя новую абстрактную машину:
Данный код можно запустить в виде аргумента новой абстрактной машине командой new_ocaml vbcnam.exe или напрямую vbcnam.exe.
Замечание
Редактирование связей в режиме -custom вынуждает компилятор
сканировать объектные файлы .cmo для создания таблицы используемых
внешних функций.
Для того чтобы использовать внешнюю функцию в интерактивном цикле, необходимо создать новый цикл, содержащий код C функции и программу на Objective CAML с ее декларацией.
Пусть есть скомпилированный файл progC.c с функцией f_c. Создадим новый интерактивный цикл ftop:
В файле ex.ml содержится декларация внешней функции f. Благодаря этому указанная функция известна интерактивному циклу ftop, а код предоставляется объектом progC.o.
Функции C и Objective CAML не разделяют буфера файлового ввода и вывода. Пусть есть программа на C:
Для того, чтобы запись на стандартный выход проходила в правильном порядке, необходимо явно сбрасывать содержимое файловых буферов (fflush).
Полученный вывод не совсем удовлетворительный. Перепишем программу Objective CAML следующим образом:
Систематическое освобождение буфера перед каждой командой записи позволяет соблюсти порядок вывода на экран между двумя языками.
Машинное представление значений в Objective CAML отличается от C, даже для таких простых типов как целое число. Причиной этому является необходимость в сохранении дополнительной информации GC при сборке памяти. Так как представление значений Objective CAML в памяти однородно, они видны в C как единый тип value.
Каждый раз как в Objective CAML вызывается C функция с аргументами, они должны быть переведены в соответствующий тип. То же самое касается результата C функции, вызываемой из Objective CAML.
Для данной цели существует несколько макросов и функций C. Они находятся в файлах, приведенных в таблице 11.1, которые предоставлены дистрибутивом Objective CAML. Они находятся в папке LIBOCAML/caml, где LIBOCAML является папкой, в которой установлены библиотеки Objective CAML2.
Значение, тип которого value, может быть:
Куча является зоной памяти, выделяемая программе для динамически размещаемых структур данных. В программе на Objective CAML GC управляет кучей. Программа на C может в свою очередь создать данные в собственной куче и затем передать указатель на выделенное значение Objective CAML.
В таблице 11.2 проведены макросы проверки и перевода типов:
Напомним, что в C существует несколько типов для целого числа: short, int и long, тогда как в Objective CAML существует один единственный тип: int.
Для представления непосредственных значений Objective CAML используются целые числа:
В следующей C программе определена функция inspect, которая проверяет значение типа value:
Данная функция проверяет является ли аргумент целым числом. Если да, то сначала на экран выводится значение в виде int C, а затем значение, переведенное макросом Long_val в целое C (long).
Как видно из следующего примера, представление целых числе в Objective CAML отличается от целых C:
Другие стандартные типы, как например char и char представленные непосредственными значениями.
Определим тип foo в Objective CAML:
Функция inspect выводит различный результат В зависимости от конструктора, функционального или константного,
Когда функция распознает непосредственное значение, она выводит "физическое" содержимое этого значения в скобках (т.е. значение в виде целого числа со знаком, занимающего одно машинное слово – int в C), а затем выводит "логическое" содержимое (значение, полученное макросами перевода типов).
В приведенных примерах, мы видим разницу между "физическим" и "логическим" содержимым. Она обусловлена бит–тегом3, который используется GC для того, чтобы различить непосредственное значение от указателя (см. главу 8 на стр. ??).
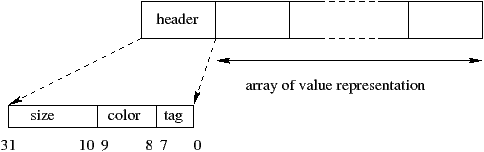
Кроме непосредственных, все остальные значения являются структурными значениями Objective CAML: n-уплеты, непустые списки, конструкторы с одним и более аргументов, векторы, записи, замыкания и абстрактные значения. Память для них выделяется в куче в виде блоков. У каждого блока имеется заголовок, содержащий информацию о содержимом блока и размере блока в машинных словах. На изображении 11.3 нарисована структура блока для компьютера со словом длинной в 32 бита.
Два "цветных" бита используются GC при прохождении графа значений в куче (см. 8, стр ??). Поле "тег" указывает на "тип" значения, которое содержится в блоке. В таблице 11.3 перечисляются функции, возвращающие эту информацию.
В таблице 11.4 указаны различные значения тегов.
from 0 to No_scan_tag-1 вектор значений value Objective CAML Closure_tag замыкание String_tag строка символов Double_tag вещественное число двойной точности Double_array_tag вектор вещественных чисел Abstract_tag абстрактный тип данных Final_tag абстрактный тип данных с завершающей функцией
Table 11.4: Описание тегов блоков памяти
В зависимости от значения, которое возвращается функцией Tag_val, используются разные макросы для доступа к блоку памяти. Если оно меньше чем No_scan_tag, то структура блока памяти это массив значений value. Макросы, для получения значений из блока памяти описаны в таблице 11.5. В соответствии с языком C и Objective CAML, первый элемент массива находится по индексу 0.
Field(v,n) возвращает n-ое значение вектора Code_val(v) возвращает code pointer для замыкания string_length(v) возвращает длину строки Byte(v,n) возвращает n-ый символ строки, в виде типа char Byte_u(v,n) то же самое, но возвращает тип unsigned char String_val(v) возвращает строку с типом C (char *) Double_val(v) возвращает вещественное Double_field(v,n) возвращает n-ый элемент вектора вещественных
Table 11.5: Доступ к элементам блока
Как и для непосредственных значений, определим функцию просмотра блока памяти. C функция print_block проверяет входной аргумент (тип value) является ли он непосредственным значением или блоком памяти. Если он оказывается блоком памяти, то функция выведет тип блока и его значение. Данная функция вызывается из функции inspect_block, которая будет вызвана из программы Objective CAML.
Различные значения типов блока обрабатываются оператором switch. Определим функцию inspect.
Эта функция используется для описания структурных значений Objective CAML. Входной аргумент не должен быть в виде замкнутой (кольцевой) структуры, иначе функция зациклится.
Массивы и n-уплеты представлены в виде массивов value.
Массивы типов value используются для представления записей Objective CAML в том же порядке что и декларация типов. Тот факт, что поле является изменяемым или нет, не влияет на его физическое представление.
Warning
C функции могут беспрепятственно физически изменить неизменяемые значения
Objective CAML. Контроль за соответствием использования функций C лежит плечах
разработчика.
Как мы уже видели, константные конструкторы представлены целыми числами. Для представления других конструкторов используется вектор, в котором содержатся аргументы конструктора. Конструктор распознается по значению тега. Этот тег соответствует порядку определения конструктора в типе: 0 соответствует первому конструктору, 1 второму и т.д.
Тип list это тип сумма, которая определена следующим образом:
У данного типа всего один неконстантный конструктор (::) с единственным тегом 0.
Каждый символ строки занимает один байт. Таким образом блок памяти, представляющий строку, хранит 4 символа в одном машинном слове (на 32 битной архитектуре).
Warning
В строках Objective CAML может содержатся символ с кодом ASCII 0, что
соответствует символу конца строки в C.
Конец строки в Objective CAML определяется с помощью размера блока, из которого она состоит, а также с помощью последнего байта последнего слова блока, в котором указывается число неиспользованных байтов в последнем слове. На следующем примере станет понятней роль последнего байта.
В двух последних примерах (“abcd” et “abcd
000”) длина строк
соответственно 4 и 5 символов. По этой причине последний байт меняет свое
значение.
В Objective CAML имеется всего один тип для чисел с плавающей запятой: float. Значения для типа float выделяются в куче и имеют размер в 2 машинных слова.
Вектор вещественных значений имеет специальную структуру, которая позволяет оптимально использовать память. По этой причине у такого вектора имеется специальный, отличный от других тегов макрос доступа.
Благодаря данной оптимизации Objective CAML может выполнять числовые расчеты с подобным типом данных намного быстрее, чем при использовании указателя на кучу.
Warning
Когда в C необходимо выделить вектор для вещественных чисел Objective
CAML, размер вектора вычисляется по следующей формуле: число элементов
помноженное на Double_wosize. Данный макрос указывает число слов
необходимых для вещественных чисел с двойной точностью.
За исключением float array, вещественные содержащиеся в других
структурах данных сохраняют их обычную представление, то есть как структурное
значение, выделенное в куче. В следующем примере анализируется список
вещественных.
Список виден как блок размером в два слова, в которых содержится заголовок и хвост списка. Заголовок списка это вещественное, также размером в два слова.
Функциональное значение характеризуется кодом с одной стороны и окружением с другой (см. 1 на стр. ??). Существует два способа, с помощью которых можно получить функциональное значение: явно использовать абстракцию (как например в fun x -> x+1) или частично применить функцию ((fun x -> fun y -> x+y) 1).
В окружении замыкания может находится 3 типа переменных: глобальные, локальные и унаследованные частичным применением. Реализация все трех категорий переменных различна. Глобальные переменные являются частью глобального окружения и явно не видны в окружении замыкания. Как мы увидим далее, локальные и унаследованные частичным применением параметры могут находится в замыкании. Таким образом, с точки зрения реализации, окружение замыкания касается лишь локальных и абстрактных параметров.
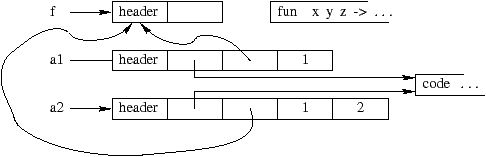
Если окружение замыкания пусто, то в нем имеется лишь указатель на код.
Если она получена частичным применением какой–нибудь абстракции, без локального объявления, это замыкание будет содержать лишь значения для каждого параметра и замыкание без окружения.
На рис. 11.4 графически изображен предыдущий вывод.
В функции f отсутствуют свободные переменные. Для замыкания без окружения, указатель кода указывает на код, который необходимо применить, когда все необходимые аргументы будут указаны, то есть в данном случае это x+y+z. Замыкание с окружением указывает на один и тот же общий код (здесь один и тот же код для a1 и a2). Данный код проверяет что все необходимые аргументы на месте и в этом случае они проталкиваются и код выполняется. В противном случае будет создано новое замыкание, с окружением в котором как всегда на первом месте указатель на замыкание без окружения из которого частичное замыкание получено. Это позволяет запустить реальный код с одной стороны и хранить указатель на самого себя для рекурсивных функций.
В случае когда используется локальная декларация, частичное применение выглядит так:
Вызов замыкания Objective CAML из C рассмотрен в гл. 11.4.4.
Значение абстрактного типа представлено вектором значений value. На самом деле, информация о типе нужна лишь синтезатору типов. Во время выполнения программы информация о типе не требуется, лишь только GC необходимо знать представление в памяти и размер значений.