Модель, по которой процессор выполняет программу, соответствует императивному программированию. Программа — это набор машинных инструкций, выполнение которых приводит к изменению памяти компьютера. Память состоит в основном из значений созданных или манипулируемых программой. Как и любой другой ресурс компьютера, память имеет свой предел. Поэтому программа, пытающаяся заполучить больше памяти, чем количество которое может ей выделить система, окажется в неверном состоянии. По этой причине необходимо оптимизировать использование памяти. Для этого нужно освободить в памяти место, занимаемое значениями, в которых программа больше не нуждается. Такое управление памятью серьезно сказывается на выполнении и эффективности программы.
Действие по резервированию памяти, для ее последующего использования, называется выделением памяти. Различают статическое выделение, которое реализуется в момент загрузки программы, до ее выполнения, и динамическое выделение, происходящее во время выполнения программы. Память, выделенная статически, остается зарезервированной до конца выполнения программы, а динамически выделенная память может быть освобождена и использована затем для других целей.
Подобное управление памятью может привести к следующим трудностям:
Чтобы избежать подобные проблемы, управление памятью требует от программиста осторожности и внимания. Данная задача может оказаться нелегкой, если в программе имеются сложные структуры данных, в особенности если они совместно используют участки памяти.
На сегодняшний день во многих языках программирования существуют механизмы автоматической сборки памяти, облегчающие задачу программиста. Основная идея заключается в том, что программе необходимы только те динамически выделенные участки памяти, на которые она указывает напрямую или косвенно. Все другие значения в памяти, адрес которых больше не доступен, могут быть высвобождены. Подобное высвобождение памяти может произойти сразу после того как значение больше не используется или позже, когда программе понадобится больше памяти, чем она располагает.
В Objective CAML существует подобный механизм, называемый GC (от английского Garbage Collector или сборщик мусора). Память выделяется в момент создания значения (то есть при использовании конструктора) и не явно освобождается. Большинству программ нет необходимости даже знать о существовании GC. Однако подобный механизм может серьезно повлиять на эффективность программ, в которой очень часто создаются новые значения. В подобных случаях бывает необходимо знать параметры GC или даже явно вызывать сборщик мусора. Для того чтобы правильно создать интерфейс между Objective CAML и другим языком программирования (см. гл. 11), нужно конкретно представлять себе каким образом GC влияет на представление данных.
В данной главе мы расмотрим динамическое выделение и различные алгоритмы освобождения памяти. В особенности будет рассмотрен сборщик мусора Objective CAML, который является сочетанием этих алгоритмов. В начале проделаем обзор различных классов памяти и их особенностей. Затем опишем выделение памяти, а так же сравним ее явное и не явное освобождение. В третьей части представлены основные алгоритмы высвобождения памяти, а в четвертой мы детально рассмотрим сборщик Objective CAML. В следующей части будет приведен пример использования GC для контроля области динамически распределяемой памяти (куча). В последней части представляются достоинства слабых указателей из одноименного модуля Weak при создании кэша памяти.
Программа на машинном языке это последовательность инструкций, которые изменяют память. Память обычно состоит из следующих частей:
Только стек и куча могут динамически менять свой размер во время исполнения программы. В зависимости от языка программирования, может существовать или нет определенный контроль указанных элементов памяти. При динамической загрузке (см. стр. ??) код размещается в динамической зоне памяти.
Большинство языков позволяют динамически выделять память. Для примера можно привести C, Pascal, Lisp, ML, SmallTalk, C++, Java, Ada.
Различают два типа выделения памяти:
Вызовы new в Pascal или malloc в C соответствуют первому случаю. Они возвращают указатель на зону памяти (то есть адрес), при помощи которого можно прочитать или изменить значение хранимое в этой памяти. Второй случай соответствует функциям создания (конструкции) значений в Objective CAML или объектно–ориентированных языков. В ОО языках экземпляры класса создаются при помощи оператора new, которому передается конструктор класса. Конструктору в свою очередь можно передать параметры. В функциональных языках при определении структурных значений (пара, список, запись, вектор, замыкание) вызывается конструктор.
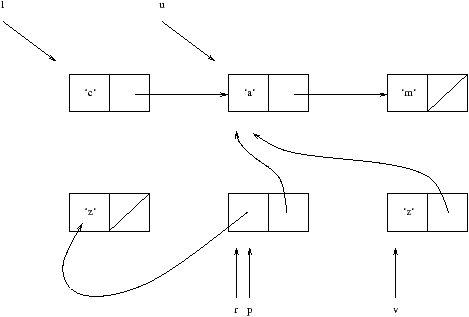
Рассмотрим конструкцию значения в Objective CAML на примере. На рисунке 8.1 изображено представление значения в памяти.
На рисунке элемент списка представлен как кортеж из двух слов, в первом хранится символ, а во втором указатель на следующий элемент списка. На самом деле все обстоит немного иначе, детали будут рассмотрены в главе о связке с языком C (см. стр. ??).
Сначала создается значение l, для каждой ячейки списка `['c';'a';'m']' вызывается конструктор (::). Глобальное объявление u соответствует хвосту списка l. В данном примере значения разделяются между l и u, то есть между аргументом функции List.tl и ее результатом. После вычисления данного выражения лишь u продолжает существовать (l прекращает существовать).
Затем создается список из одного элемента, потом пара r в которой содержится этот список и список u. Эта пара сопоставляется с образом, при этом она переименуется сопоставлением в p. После этого первый элемент p объединяется с его вторым элементом, откуда получаем список `['z';'a';'m']' связанный с глобальным идентификатором v. Заметим, что результат snd (список `['a';'m']') разделяется с p, тогда как результат fst (символ ``z`') копируется.
Во всех этих случаях, происходит явное выделение памяти, то есть запрошенное программистом (в виде инструкции или выражения языка).
Замечание
При выделении памяти, сохраняется информация о размере выделеного
объекта. Это необходимо для последующего высвобождения.
В языках программирования, с явным освобождением памяти, существует специальный оператор освобождения (free в C или dispose в Pascal), которому передается адрес (указатель) объекта, который нужно освободить. путные синонимы Используя сохраненную во время выделения памяти информацию, программа высвобождает участок памяти и он может быть использован в последствии.
Динамическое выделение памяти обычно используется для меняющихся структур данных, например списки, деревья и т.д. Освобождения памяти занимаемого такими структурами не делается “одним движением”, а при помощи функции, которая проходится по всем элементам структуры. Такие функции называются десктрукторами.
Не трудно корректно определить подобную функцию, однако ее использование может оказаться сложной задачей. Действительно, для того чтобы освободить память занимаемую структурой, нужно пройтись по всем ее указателям и применить к ним оператор освобождения памяти. Может оказаться правильным предоставить эту задачу программисту, так как он лучше знает свои данные и как их освобождать. Однако неправильное использование указанных операторов можно привести к ошибке выполнения программы. Основные трудности заключаются в следующем:
Знать длительность существования всего множества значений программы есть основная трудность явного высвобождения памяти.
В языках программирования с неявным освобождением памяти не существует операторов освобождения памяти. Программист не может высвободить память занятую значением. Вместо этого, срабатывает сборщик памяти для неиспользуемого значения, то есть на которое больше никто не ссылается. Сборщик так может быть запущен в случае нехватки памяти.
Алгоритм автоматического высвобождения памяти является в какой–то мере глобальным деструктором. Из–за этой особенности концепция и реализация такого деструктора намного сложней, чем деструктора специфичного для определенной структуры данных. Однако, если данная трудность преодолена, автоматическая сборка памяти значительно повышает надежность управления памяти. В частности, исчезает риск появления повисших указателей.
Автоматическая сборка помяти вносит следующие улучшения область динамически распределяемой памяти (куча):
При выборе архитектуры GC необходимо учитывать определенные критерии и ограничения:
В реальности, главным критерием является надежность, в связи с чем GC находят компромисс между остальными ограничениями.
Различают два класса алгоритмов автоматической сборки памяти:
Алгоритмы–разведчики более часто используются в языках программирования. Счетчик ссылок загружает систему (обновление ссылок) даже когда нечего высвобождать.
Каждой выделенной зоне памяти ассоциируется счетчик, который хранит число указателей на данный объект. Он увеличивается при каждом новом указателе и уменьшается когда указатель исчезает. Зона памяти высвобождается, когда счетчик равен 0.
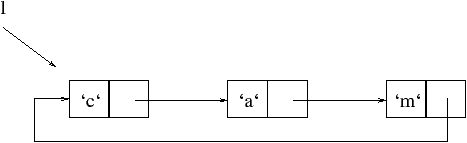
Выгода такой системы заключается, в том что зона памяти высвобождается сразу же после того как она перестала использоваться. Кроме того, что такой сборщик загружает систему, он не умеет обращаться с круговыми (циклическими) объектами. Предположим что Objective CAML обладает таким сборщиком. В следующем примере создается временное значение l — список символов, где последнее звено указывает на ячейку с 'c'. Данный список является циклическим (изб. 8.2).
К концу вычисления данного выражения, у каждого элемента списка l счетчик будет равен 1 (даже у первого, так как список циклический). Однако данное значение больше не доступно и не сможет быть высвобождено, так как его счетчик не равен нулю. В языках программирования использующих сборщик с алгоритмом счетчика ссылок, как например Python, и разрешающих циклические значения необходимо предусмотреть дополнительный алгоритм–разведчик памяти.
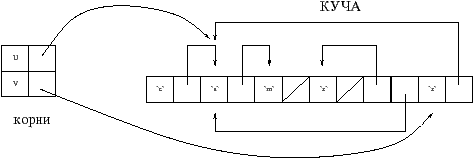
Алгоритм–разведчик обследует граф доступных значений кучи. Для этого он использует множество корней, которые указывают на начало поиска. Данные корни находятся вне кучи, чаще всего они хранятся в стеке. Предположим, что в приведенном выше примере изб. 8.1, значения u и v являются частью корней. Если начать обход, начиная с этих значений, то получим граф значений, которые необходимо сохранить: звенья и указатели обведенные жирной линией на изб. 8.3.
При обходе графа необходимо уметь различать непосредственные значение от указателей. Если корень указывает на целое число, то не стоит его рассматривать как адрес другой ячейки в памяти. В функциональных языках для этого используются несколько битов каждой ячейки кучи — биты маркировки (tag bits). По этой причине в целых числах Objective CAML используется лишь 31 бит. Эта особенность обсуждается в главе 11, стр. ??. Существуют другие решения чтобы различить указатель от непосредственного значения, они будут описаны на стр. ??.
Приведем два следующих наиболее используемых алгоритма: Mark&Sweep и Stop&Copy. Первый создает список свободных ячеек кучи, а второй копирует еще “живые” ячейки во вторичную зону памяти.
Необходимо представить себе кучу как вектор ячеек памяти. Состояние кучи примера 8.1 изображено на 8.4.
Качества алгоритма–разведчика определяются следующими свойствами:
Свойство локализации, при просмотре структурированного значения, позволяет избежать перехода на другую страницу памяти. Компактность предназначена для того чтобы избежать фрагментация памяти, и в то же время выделить блок памяти размером во всю доступную память. Эффективность, фактор сборки памяти и необходимость в дополнительной памяти тесно связаны с временной и пространственной сложностью алгоритма.
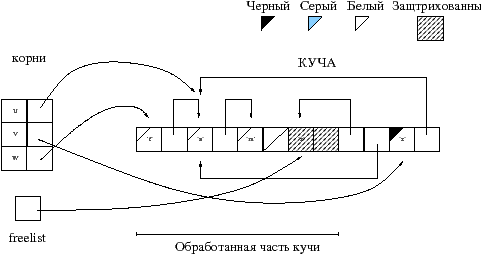
Основная идея алгоритма Mark&Sweep заключается в том, что он поддерживает список свободных ячеек памяти кучи, называемый freelist. Этот список проверяется для каждого запроса выделения памяти. Если он пуст или количество свободных ячеек недостаточно, то выполняется Mark&Sweep.
Алгоритм действует в два этапа:
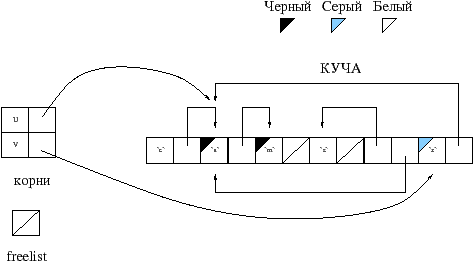
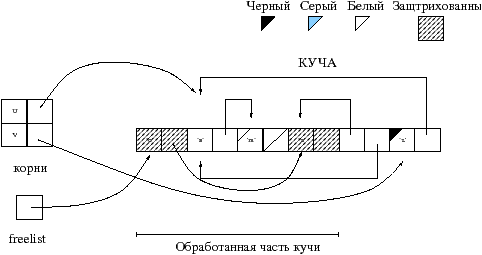
Проиллюстрируем управление памятью алгоритмом Mark&Sweep изображением, на котором воспользуемся четырьмя цветами: белый, серый 1, черный и заштрихованный. Для этапа маркировки применяется черный и серый цвет, для восстановления заштрихованный и для выделения памяти белый.
Смысл цветов во время маркировки следующий:
Необходимо хранить множество серых ячеек, для того чтобы удостоверится в том что все проверено. По окончании маркировки все ячейки либо белые либо черные. Ячейки, которые были достигнуты начиная от корней, помечены черным цветом. На рисунке 8.5 изображен промежуточный этап маркировки предыдущего примера 8.4: корень u был уже обработан, а v еще нет.
Список свободных ячеек создается в течении этапа восстановления. Для того этапа используются следующие света:
На рисунке 8.6 изображено изменение кучи и создание freelist.
Перечислим характеристики алгоритма Mark&Sweep:
Этап маркировки чаще всего реализован рекурсивной функцией и как следствие она использует часть стека выполнения. Мы могли бы провести полностью итеративную версию алгоритма Mark&Sweep, которая бы не использовала стек неизвестной глубины, но в итоге рекурсивная версия оказывается более эффективной.
Для функционирования алгоритму Mark&Sweep необходимо знать размер значений. Он хранится либо в самих значениях, либо вычтен из адресов памяти, разделением кучи на зону объектов с ограниченным размером. Этот алгоритм, используемый с первых версий Lisp, до сих пор широко применяется. Часть GC Objective CAML использует подобный алгоритм.
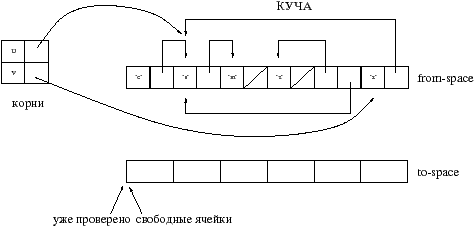
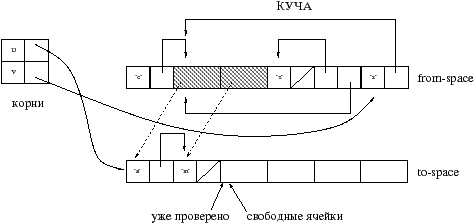
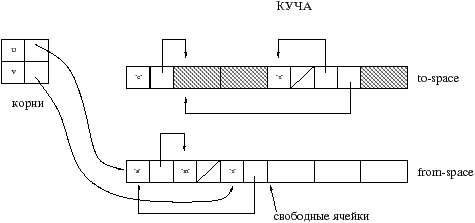
Основным принципом алгоритма Stop&Copy является использование вторичной памяти для копирования и сжатия данных. Куча разбита на две части: используемая зона (называемая from–space) и зона копирования (to–space).
Принцип действия следующий. Начиная от корней скопировать все значения из from–space в to–space. При этом сохраняем новый адрес перенесенного значения (чаще все новый адрес сохраняется на старом месте значения), для того чтобы обновить все другие значения указывающие на текущее.
Содержимое скопированных ячеек формирует новые корни. До тех пор пока все корни не будут обработаны, алгоритм продолжает выполнятся.
В случае разделения, то есть когда копируемое значение уже скопировано, мы лишь указываем новый адрес значения.
По окончанию работы GC все корни обновлены и указывают на новые адреса. Обе зоны меняются ролями для будущего GC.
Перечислим основные характеристики алгоритма Stop&Copy:
Существует немало других алгоритмов GC, многие из них основываются на двух предыдущих алгоритмов. Часто такие алгоритмы созданный специально для определенных проблем, как например для вычисления больших матриц, или же они зависят от типа компиляции. В Generational GC возможны оптимизации основанные на “возрасте” значения. Conservative GC используется в тех случаях, когда нет явной разницы между указателями и непосредственными значениями (например когда компилируем в код C). И наконец Incremental GC позволяет избежать замедления вызванного работой GC.
Функциональные программы используют большое количество памяти и замечено, что очень много значений имеют очень короткое существование2. С другой стороны, если какое-то значение выжило несколько GC, то вполне возможно что это значение будет еще долго существовать. Чтобы не обходить каждый раз всю кучу, как это делает алгоритм Mark&Sweep, во время высвобождения памяти, желательно чтобы GC проверял лишь значения “выжившие” после одного или нескольких GC (то есть новые значения). Чаще всего в этой области памяти мы высвобождаем больше места. С этой целью объекты помечаются либо временем либо числом GC которые они “пережили”. Для оптимизации GC используются различные алгоритмы в зависимости от возраста значений:
Стареющее значение будет все меньше и меньше обследоваться частыми GC. Трудность заключается в том чтобы анализировать часть памяти содержащую лишь молодые объекты. В чистых функциональных языках, то есть где нет физического изменения, молодые объекты могут указывать на старые, но старые не могут указывать на молодые, так как те появились позже. Таким образом подобный механизм хорошо подходит функциональным языкам, за исключением тех, где имеет место отложенное вычисление, которое позволяет расчитать элементы структуры, после расчета этой самой структуры. Однако в нечистых функциональных языках всегда можно изменить часть значения старого объекта, что бы она ссылалась на более молодой. Теперь же проблема заключается в том, чтобы определить зону памяти только с молодыми объектами на которые указывают старые. Для этого нужно создать таблицу ссылок старых объектов на молодые, что позволит нам получить правильные GC. В следующей части, мы рассмотрим GC Objective CAML.
До сих пор предполагалось что мы можем отличить указатель от немеделенного (атомарного) значения. Необходимо отметить, что в функциональных языках с параметризуемым полиморфизмом все значения занимают одно слово памяти3. Это свойство позволяет иметь общий (generic) код полиморфных функций.
Однако, ограничение множества целых чисел может быть недопустимым. В этом случае, conservative garbage collectors позволяют избежать маркировки немеделенных значений как целых и значения используют целое слово памяти без всяких меток. Чтобы не обходить зоны памяти с корня содержащего целое число, используется алгоритм различающий немедленные значения и корректные указатели. Этот алгоритм основывается на двух предположениях:
Таким образ любое правильное, по отношению к адресам кучи, значение будет рассмотрено как указатель и будет сохранено GC, даже если на самом деле это немедленное значение. С использованием специальных страниц памяти под объекты разного размера такие случаи могут стать очень редкими. Недостатком данного алгоритма является отсутствие гарантии, что вся неиспользуемая память будет восстановлена. Однако, мы уверены, что восстанавливается лишь неиспользуемая память.
Чаще всего, conservative garbage collectors не перемещают значения (отсюда название — консервативный). Действительно, в связи с тем что GC рассматривает некоторые немедленные значения как указатели, было бы ущербно его переносить. Однако, в создание множества корней могут быть внесены особенности, позволяющие с уверенностью перенести часть памяти, которая соответствует “правильным” корням.
Такая схема действия GC часто используется при компиляции функционального языка в язык C, который рассматривается как переносимый ассемблер. При этом немедленные значения C занимают целое слово памяти.
Одним из часто упоминаемых недостатков GC является заметная пользователю остановка выполняющейся программы и при чем на неопределенное время. Первый случай может вызывать неудобство для определенного круга программ. Например, игры в стиле action. Ее остановка на несколько секунд будет плохо воспринята игроком, так как игра продолжится так же неожиданно как и была приостановлена. Второй случай приводит к потере контроля над программами, которые обрабатывают определенные события в реальном времени. Типичный пример — встроенные программы контролирующие автомобиль или станок. Подобные программы реального времени, которые должны реагировать в ограниченный период времени, избегают использование GC.
Incremental Garbage Collection должны обладать способностью остановитвся в любой момент и затем продолжить свою работу, гарантируя безопасность высвобождения памяти. Такие сборщики дают неплохие результаты для первого случая. Они так же могут быть использованы во втором случае, если соблюдать следующую дисциплину программирования: четко разделять код на части которые используют динамическое выделения памяти и те которые не используют.
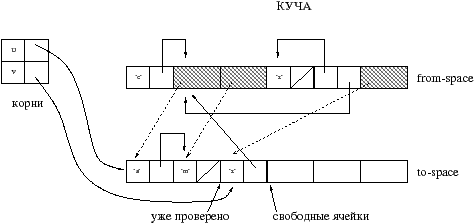
Вернемся к примеру Mark&Sweep и рассмотрим те изменения, которые необходимо сделать, что этот алгоритм стал инкрементальный. В принципе, таких изменений всего два:
Если алгоритм Mark&Sweep приостановлен во время процесса Mark, необходимо обеспечить чтобы память выделенная между остановкой маркировкой и затем возобновлением не была высвобождена во время Sweep. Для этого, ячейки памяти выделенные в подобный промежуток, заранее помечаются черным или серым цветом.
Если алгоритм Mark&Sweep приостановлен в момент Sweep, то он может быть затем продолжен как обычно “перекрашивая” выделенные ячейки памяти белым цветом. Действительно, во время этапа Sweep вся куча последовательно просматривается и память, выделенная во время приостановки сборщика, находится впереди точки, с которой алгоритм продолжит свою работу. Таким образом эта память не будет проверена до следующего цикла GC.
На рисунке 8.12 изображено выделение памяти во время этапа высвобождения памяти. Корень w создан следующим кодом:
Сборщик мусора Objective CAML использует различные методы, которые мы привели в предыдущей части. Сборщик OCaml является сборщиком с двумя поколениями: новое и старое. Для молодых поколений используется в основном алгоритм Stop&Copy (minor garbage collection) и инкрементальный Mark&Sweep для старых поколений (major garbage collection).
Объект молодого поколения, который продолжает существовать после минорного GC перемещается в старое поколение. Пространство to–space используется алгоритмом Stop&Copy как пространство старого поколения. По окончанию этого процесса, пространство from–space полностью свободно.
Когда мы затронули тему сборщиков с поколениями, мы отметили проблему нечистых функциональных языков: значение старого поколения может ссылаться на объект из нового поколения. Небольшой пример:
Предполагается что на месте комментариев имеется большая последовательность кода, во время которой значение older переходит в старое поколение. Минорный GC должен учитывать некоторые значения старого поколения. То есть необходимо поддерживать таблицу ссылок объектов старого поколения на объекты нового, которые становятся частью корней минорного GC. Эта таблица почти не увеличивается и к концу минорного GC она становится пустой.
Напомним, что Mark&Sweep старого поколения — инкрементальный, то есть часть мажорного GC выполняется во время каждого минорного GC. Мажорный GC — это Mark&Sweep, который следует алгоритму описанному на стр. ??. Выгода в подобном подходе заключается в уменьшении времени ожидания мажорного GC, предварительном выполнении фазы маркировки во время каждого минорного GC. Когда запускается мажорный GC, процесс маркировки необработанных областей уже законен и этап сборки памяти запущен. Так как алгоритм Mark&Sweep может привести с сильной фрагментации памяти, по этой причине процесс сжатия памяти может быть запущен после мажорного GC.
В сумме, мы получаем следующие этапы:
Модуль GC позволяет запустить один из этапов GC.
Особенность сборщика Objective CAML в том что размер кучи не фиксирован в начале программы, он может увеличиваться или уменьшатся по мере необходимости программы.
При помощи этого модуля мы можем контролировать кучу, получить различную информацию о ее использовании, а так же запустить различные этапы сборщика. В данном модуле определены две записи: stat и control. Тип полей записи control модифицируемый и при их помощи можно контролировать поведение сборщика. Поля записи stat нельзя изменить, они ли)ь отражают состояние сборщика данный момент.
Поля записи stat содержат следующие счетчики:
В записи control имеются следующие записи:
Приведем следующие функции манипулирующие типами stat и control в таблице 8.1.
При помощи следующих функций типа unit -> unit можно принудительно выполнить определенные этапы GC: minor (первый этап), major (первый и второй этапы), full_major (первый, второй и третий этапы), compact (первый, второй, третий и четвертый этапы).
Здесь мы видим число запусков различных этапов: минорный GC, мажорный GC и сжатие, а так же число слов обработанных различными частями памяти. Вызов compact принудительно выполняет все четыре этапа GC и изменяет статистическую информацию о куче (см. вызов Gc.stat).
Поля GC.minor_collections и compactions увеличены на 1, тогда как поле Gc.major_collections увеличено на 2. Все поля типа GC.control является изменяемыми. Для того чтобы изменения вошли в силу, необходимо использовать функцию Gc.set. Эта функция ожидает на входе значение типа control и изменяет поведение GC.
Поле verbose может иметь значения от 0 до 127, активируя 7 различных индикаторов.
И получим следующий вывод на экране:
Здесь выводятся различные этапы GC и число обработанных объектов.
Слабый указатель (weak pointer) это указатель, память которого может быть высвобождена GC в любой момент. Это может звучать странно, что значение может исчезнуть в любой момент. В действительности необходимо рассматривать эти указатели как хранилище еще пока доступных значений. Подобное свойство может оказаться очень полезным в случае если мы располагаем не большой по сравнению с сохраняемыми элементами памятью. Классический примером является управление кэшем: значение может быть утеряно, но оно остается доступных, до тех пока оно существует.
В Objective CAML нет возможности управлять единичным слабым указателем, а лишь вектором указателей. В модуле Weak определен абстрактный тип 'a Weak.t, который соответствует абстрактному типу 'a option array, вектор слабых указателей типа 'a. Конкретный тип 'a option определяется следующим образом:
В таблице 8.2 представлены основные функции данного модуля.
Функция create выделяет пространство для вектора слабых указателей, каждый элемент вектора инициализирован значением None. Функция set устанавливает значение типа 'a Option по указанному индексу вектора. Функция get возвращает значение расположенное по указанному индексу в векторе. Полученное значение вносится в множество корней GC и не может быть высвобождено до тех пор пока не него существуют ссылки. Для того чтобы проверить существует ли желаемое значение, можно использовать либо функцию check, либо сопоставлением с образцом типа 'a Option. Первый вариант не зависит от представления слабых указателей в памяти.
Так же существуют обычные функции для линейных данных: length для определения длинны, fill и blit для копирования частей вектора.
Довольно часто в графических программах открыто сразу несколько изображений. Когда мы переключаемся с одного изображения на другое, первое сохраняется на диск, а второе загружается из другого файла. Обычно, программа хранит имена послених обработанных изображений. Во избежание постоянного доступа к диску и эффективного использования памяти, используется кэш хранящий последние загруженные изображения. Содержимое кэша изображений может быть очищенной в любой момент по необходимости. Такой кэш реализуется в виде вектора слабых указателей и управление кэшем доверяется GC. Во время загрузки изображения, сначала проверяется присутствует ли оно уже в кэше, если да, то оно становится текущим изображением, иначе оно загружается с диска.
Вектор изображений реализуется следуищим способом:
В поле size хранится размер вектора, ind является индексом текущего изображения, в name хранится имя текущего изображения, в поле current содержится текущее изображение,а вектор cache хранит слабые указатели на изображения. В этом векторе содержатся последние загруженные изображения и их имена.
Функция init_table инициализирует вектор начальными изображениями.
При загрузке нового изображения, текущее сохраняется в векторе и затем загружается новое изображение. Перед этим, необходимо просмотреть кэш, на случай если искомое изображение уже загружено.
Функция load_table проверяет является ли запрашиваемое изображение текущим, если нет, то проверка продолжается в кэше и в конечном итоге загружается с диска если поиск в кэше ничего не дал. В последних двух случаях это изображение становится текущим.
Для того чтобы проверить эту функцию, воспользуемся следующим кодом, выводящий содержимое кэша:
Протестируем конечную программу:
Этот механизм кэша может быть использован в различных случаях.
В данной главе были приведены различные алгоритмы высвобождения памяти. Это было сделано с целью представить алгоритм используемый Objective CAML. GC Objective CAML является инкрементальным GC, с двумя поколениями значений. Он использует алгоритм Mark&Sweep для старого поколения и Stop&Copy для молодого. Два модуля, напрямую связанные с GC, позволяют контролировать состояние кучи. При помощи модуля Gc мы можем проанализировать поведение кучи и изменить некоторые ее параметры, чтобы оптимизировать ее для определенных приложений. При помощи модуля Weak мы можем сохранить в векторе потенциально высвобождаемые, но еще доступные значения. Это свойство бывает полезным для реализации кэша памяти.