Преимущество одного языка программирования над другим заключается в простоте разработки качественных программ и легком сопровождении программного обеспечения. Первая часть книги, посвященная представлению языка Objective CAML, вполне естественно завершится реализацией нескольких программ.
В первой программе мы реализуем несколько функций запрашивающих информацию из базы данных. Наше внимание будет акцентировано на функциональном стиле программирования и использование списков. Таким образом пользователь будет иметь набор функций для формулирования и выполнения запросов прямо в языке Objective CAML. В этом примере мы покажем разработчику как он может с легкостью предоставить набор функций необходимых пользователю.
Вторая программа это интерпретатор BASIC1. Напомним, что подобные императивные языки принесли немалый успех первым микрокомпьютерам. Двадцать лет спустя, реализация таких языков является простой задачей. Несмотря на то что BASIC императивный язык, для написания интерпретатора мы воспользуемся функциональной частью Objective CAML, в частности для вычисления инструкций. Однако, для лексического и синтаксического анализа мы используем физически изменяемую структуру данных.
Третья программа — всем известная игра Minesweeper, которая входит в стандартный дистрибутив Windows. Цель игры — найти все спрятанные мины, исследуя рядом расположенные ячейки. Для реализации мы воспользуемся императивной частью языка, так как поле игры представлено в виде матрицы, которая будет изменятся после каждого хода игрока. Мы, также используем модуль Graphics для реализации интерфейса игры и обработки событий. Вычисление автоматически открывающихся ячеек будет сделано в функциональном стиле.
Данная программа использует модуль Graphics описанный в 4 главе (см. стр. ??) и несколько функций из модулей Random и Sys из главы 7 (см. стр. ?? и ??).
Реализация базы данных, ее интерфейса и языка запросов — слишком амбициозный проект для данной книги и для знаний читателя в Objective CAML на данный момент. Тем не менее, ограничив задачу и используя лучшие возможности функционального программирования, можно реализовать достаточно интересное средство для обработки запросов. Мы изучим как использовать итераторы и частичное применение для написания и выполнения запросов. Также, мы увидим использование типа данных инкапсулирующих функциональные значения.
В этом примере мы будем работать над базой данных содержащей информацию о членах ассоциации. База храниться в файле association.dat.
Для хранения данных, большинство баз данных используют свой собственный, так называемый “проприетарный” формат. Чаще всего, есть возможность экспортировать эти данные в текстовый формат. Вот одна из возможных структур:
Файл ассоциации начинается так:
Num|Lastname|Firstname|Address|Tel|Email|Pref|Date|Amount 0:Chailloux:Emmanuel:Universite P6:0144274427:ec@lip6.fr:email:25.12.1998:100.00 1:Manoury:Pascal:Laboratoire PPS::pm@lip6.fr:mail:03.03.1997:150.00 2:Pagano:Bruno:Cristal:0139633963::mail:25.12.1998:150.00 3:Baro:Sylvain::0144274427:baro@pps.fr:email:01.03.1999:50.00
Теперь необходимо выбрать формат в котором программа будет хранить данные базы. У нас есть выбор: список или вектор карточек. Списком легче манипулировать; добавление и удаление карточек являются простыми операциями. Зато векторы предоставляют одинаковое время доступа к любой карточке. Так как мы желаем использовать все карточки, а не какие-то конкретно, каждый запрос обрабатывает все множество карточек. По этой причине мы выбираем списки. Для карточек у нас тот же самый выбор: список или вектор строк? В этом случае ситуация обратная; с одной стороны формат карточки зафиксирован для всей базы данных и мы не можем добавить новые поля. С другой стороны, в зависимости от будущих операции, мы используем лишь некоторые поля карточек, соответственно необходимо быстро получить к ним доступ.
Вполне естественным решением данной задачи будет использование вектора проиндексированного именами полей. Однако подобный тип не возможен в Objective CAML, мы воспользуемся обычным вектором (проиндексированный целыми числами) и функцией, которая возвращает имя поля в зависимости от индекса.
Реализуем доступ к полю по имени n карточки dc базы данных db при помощи следующей функции:
Мы принудительно привели тип переменной dc к data_card, тем самым наша функция field принимает лишь вектор строк, а не какой попало.
Проиллюстрируем на небольшом примере.
Выражение field base_ex “Lastname” вычисляется как функция, которая берет на вход карточку и возвращает поле “Lastname”. Используя List.map, мы применяем эту функцию к каждой карточке базы данных base_ex и в результате получаем список полей “Lastname”.
На этом примере показано, как мы собираемся использовать функциональный стиль программирования. В данном случае частичное применение функции field определяет функцию доступа к конкретному полю, независимо от числа карточек в базе данных. В то же время, в реализации функции field есть недостаток: если мы обращаемся каждый раз к одному и тому же полю, индекс вычисляется каждый раз. Мы предпочитаем следующую реализацию.
Здесь, после применения функции к аргументу, вычисляется индекс поля и используется в последующих вычислениях.
Для Objective CAML, файл с базой данных это множество линий. Наша задача состоит в том чтобы прочитать каждую линию, как строку, затем в разбить ее на части при помощи сепараторов и таким образом извлечь данные, а также данные для функции индексации полей.
Нам нужна функция split, которая будет разбивать строку в соответствии с определенным разделителем. Для этого мы воспользуемся функцией suffix, возвращающая суффикс строки s начиная с позиции i. В этом нам помогут три предопределенные функции:
Обратите внимание на обработку исключений в этой функции, в особенности исключение Not_found.
Для того чтобы получить из списка вектор, достаточно воспользоваться соответствующей функцией из модуля Array (of_list). Вычисление функции индекса из списка имени полей может показаться сложной задачей, но к счастью модуль List предоставляет нам все необходимые для этого средства.
У нас имеется список строк, значит нам нужна функция, которая ассоциирует строке индекс, то есть ее положение или номер в списке.
Для реализации этой функции, мы создаем список индексов, который мы комбинируем со списком имен полей. Таким образом вы получаем новый список ассоциаций с типом string * int list. Для того, чтобы найти индекс связанный с именем, воспользуемся специально созданной на подобный случай функцией assoc из библиотеки List. Функция mk_index возвращает функцию которая берет на входе имя и вызывает assoc с этим именем и списком построенным ранее.
Теперь мы готовы, к тому чтобы написать функцию читающую файлы базы данных в указанном формате.
Считывание записей из файл осуществляется функцией read_file, которая рекурсивно оперирует входным каналом. Конец файла оповещается исключением End_of_file. В этом случае мы закроем канал и вернем пустой список.
Считаем файл ассоциации.
Богатство и сложность обработки множества данных базы пропорциональны богатству и сложности используемого языка запросов. Так как в данном случае мы решили использовать Objective CAML в качестве языка запросов, a priori ограничений на выражение запросов нет! Мы так же хотим предоставить несколько простых средств манипуляции карточками и их данными. Для получения желанной простоты, необходимо ограничить мощь Objective CAML, для этого определим несколько целей и принципов обработки.
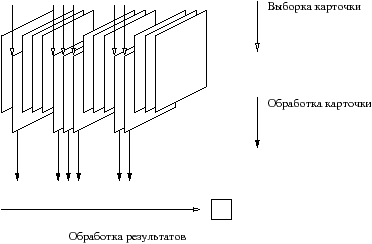
Цель обработки данных заключается в получении так называемого состояния базы. Создание такого состояния базы можно разбить на три этапа:
Что мы и изобразили на рисунке 5.1.
В соответствии с этим, нам нужно 3 функции следующих типов:
Objective CAML предоставляет три функции высшего порядка, известные как итераторы, представленные на странице ??. Они соответствуют нашей спецификации.
После того как мы определим функциональные аргументы, мы сможем воспользоваться этими функциями для реализации состояния в три этапа.
Для некоторых запросов нам понадобится следующая функция.
В случае, когда обработка данных ограничивается выводом на экран, вычислять нечего.
В следующих параграфах, мы увидим несколько простых методов обработки данных, а так же определение функций выражающих критерии выборки. Небольшой пример в заключении этой главы использует эти функции в соответствии с приведенными выше принципами.
В конкретном случае, логическая функция, которая определяет критерии выборки карточки, есть логическая комбинация свойств данных всех или части полей карточки. Каждое поле карточки, представленое строкой, может нести в себе информацию другого типа: целое число, число с плавающей запятой, etc.
Выборка определенного поля по конкретному критерию будет осуществляется при помощи следующей функции data_base -> 'a -> string -> data_card -> bool. Параметр типом 'a соответствует типу информации хранимой в поле. Имя этого поля указанно аргументом с типом string.
Определим два простых теста для работы с этим типом данных: тест на равенство с другой строкой и тест на “не пустоту” строки.
Для проверки информации содержащей числа с плавающей запятой достаточно перевести значение строки содержащей десятичное число в тип float. Вот несколько примеров полученных использованием настраиваемой функции tst_ffield :
Тип у данных функций:
Этот тип информации немного сложней, он зависит от представления даты в базе данных и требует определения способа сравнения дат.
Установим формат даты карточки как строку дд.мм.гггг. Для того чтобы получить дополнительные возможности сравнения, добавим в формат даты символ '_', заменяющий день, месяц или год. Даты сравниваются в лексикографическом порядке в формате (год, месяц, день). Для того чтобы мы могли пользоваться выражениями как “до июля 1998”, будем использовать сопоставление с образцом даты: “_.07.1998”. Сравнение даты с образцом реализуется функцией tst_dfield, которая анализирует образец и создает ad hoc сравнивающую функцию. Для того чтобы определить эту универсальную функцию проверки даты, нам понадобятся несколько дополнительных функций.
Напишем две функции преобразующие дату (ints_of_string) и образцы даты (ints_of_dpat) в триплет целых чисел. Мы заменим символ '_' образца на целое число 0.
Напишем функцию теста, которая использует отношение целых r. Здесь мы реализуем лексикографический порядок, при этом мы обрабатываем специальный случай с нулем.
Наконец, определим универсальную функцию tst_dfield со следующими аргументами: отношение r, база данных db, образец dp, имя поля nm и карточка dc. Эта функция проверяет, что образец и извлеченное поле удовлетворяют отношение.
Теперь применим функцию к трем отношениям.
Тип этих функций следующий:
data_base -> string -> string -> data_card -> bool.
Три первые аргумента проверок, которые мы определили — база данных, значение и имя поля. Когда мы пишем запросы базы данных, значения этих аргументов известны. Для базы base_ex проверка <<до июля 1998>> пишется следующим образом.
Получается, что проверка это функция имеющая тип data_card -> bool. Теперь нам нужно получить логические комбинации результатов подобных функций, примененных к одной и той же карточке. Для этого воспользуемся следующим итератором.
Здесь b — значение базы, функция c — логический оператор, fs — список функций проверки по полю и dc — карточка.
В следующем примере получаем конъюнкцию (логическое произведение) и дизъюнкцию (логическая сумма) списка проверок.
Для удобства определим отрицание функции проверки.
Для того, чтобы выбрать карточку, дата которой находится в определенном интервале, воспользуемся комбинаторными операторами.
Трудно представить себе все возможные обработки карточек или множество данных полученных после этой обработки. Тем не менее можно с уверенностью определить два класса таких обработок: численное вычисление и форматирование данных для печати. Рассмотрим каждый каждый случай на примере.
Подготовим к печати строку, содержащую имя члена ассоциации и кое-какую информацию.
Начнем с определения функции, которая из списка строк и разделителя создает строку состоящую из элемент списка разделенных сепаратором.
Определим функцию extract, которая создает список из полей с информацией, она извлекает из каждой карточки данные полей, имена которых переданы в списке.
Функция форматирования для печати выглядит следующим образом.
Аргумент ns является списком с именами полей, которые нас интересуют. Поля разделены символом табуляции (''), а строка заканчивается возвратом каретки.
Вот как можно вывести на экран имена и фамилии членов ассоциации.
Давайте вычислим сумму членских взносов для определенного множества карточек. Для этого достаточно извлечь нужное поле, привести к целому типу и вычислить сумму. Нужный результат может быть получен композицией этих функций. Для упрощения записи, определим инфиксный оператор композиции.
Воспользуемся этим оператором в следующем определении.
Аналогичным образом можно применить эту функцию ко всей базе денных.
В заключении, проиллюстрируем на примере принципы, которые мы представили ранее в этой главе.
Рассмотрим два типа запроса базы данных:
Для создания этих списков мы сначала выбираем в соответствии со значением поля “Pref” релевантные карточки, затем используем функцию format_line.
Вычисление состояния взносов выполняется по обычному принципы: выборка, затем обработка. В данном случае обработка состоит из двух частей: форматирование и вычисление общей суммы взносов.
В результате этой функции мы получим пару состоящую из списка строк с информацией и суммы взносов.
Основная программа состоит из интерактивного цикла, выводящего результат запроса, который пользователь выбрал из меню. Здесь мы используем императивный стиль программирования, за исключением вывода результата при помощи итератора.
Мы вернемся к этому примеру в главе 20, чтобы добавить к нему интерфейс при помощи web навигатора.
Вполне естественным будет добавить в базу данных нашего примера информацию о типе каждого поля. Эта информация пригодится в случае если мы хотим определить универсальные (generic) операторы сравнения со следующим типом data_base -> 'a -> string -> data_card -> bool. Имя поля (третий аргумент) позволяет передевать управление соответствующей функции сравнения и проверки.
В данном разделе мы рассмотрим интерпретатор языка Basic. Это программа, которая выполняет другие программы написанные на языке Basic. Конечно, мы ограничимся лишь частью команд этого языка, наш интерпретатор будет распознавать следующие команды:
Каждая строка программы Basic помечена номером и содержит лишь одну инструкцию. Программа, вычисляющая факториал для числа введенного с клавиатуры, выглядит следующим образом:
Реализуем также мини–редактор по принципу интерактивного цикла. У нас должна быть возможность добавлять новые строки, вывод программы и ее вычисление. Запуск предыдущей программы осуществляется командой RUN. Пример вычисления этой программы.
Это вычисление можно разбить на несколько разных этапов.
В таблице представлен конкретный синтаксис в форме BNF программы на Basic. Мы вернемся к данному способу описания языка в главе 10 на странице ??.
Unary_Op ::= - | !
Binary_Op ::= + | - | * | / | %
| = | < | > | <= | >= | <>
| & | ' | '
Expression ::= integer
| variable
| "string"
| Unary_Op Expression
| Expression Binary_Op Expression
| ( Expression )
Command ::= REM string
| GOTO integer
| LET variable = Expression
| PRINT Expression
| INPUT variable
| IF Expression THEN integer
Line ::= integer Command
Program ::= Line
| Line Program
Phrase ::= Line | RUN | LIST | END
Заметим, что правильность выражения с точки зрения грамматики не означает возможность его вычисления. Например, 1+"hello" есть выражение, однако его невозможно вычислить. Это сделано с целью облегчить абстрактный синтаксис языка Basic. Расплата за это — программы на Basic, синтаксически правильные, могут привести к ошибке из–за несоответствия типов.
Теперь определить типы данных Objective CAML просто, достаточно перевести абстрактный синтаксис в тип сумма.
Определим синтаксис команд для мини–редактора.
Обычно, чтобы облегчить синтаксис, программистам разрешается не указывать все скобки. Например, под выражением 1+3*4 подразумевается 1+(3*4). Для этого, каждому оператору языка присваивается целое число — приоритет:
Целые числа означают, так называемый, приоритет операторов. Далее мы увидим как они используются при синтаксическом анализе или выводе программ на экран.
Для того, чтобы вывести программу хранящуюся в памяти, необходимо уметь перевести строку программы из абстрактного синтаксиса в строку символов.
Перевод операторов может быть получен легко и просто:
Вывод выражений соблюдает приоритет операторов для того чтобы получить выражение с минимумом скобок. Мы используем скобки лишь в случае если оператор в под–выражении справа от оператора менее приоритетный всего оператор целого выражения. К тому же, арифметические операторы ассоциативные слева, это значит что выражение 1-2-3 эквивалентно (1-2)-3.
Чтобы получить данный результат, создадим две функции ppl и ppr, которые будут обрабатывать левые и правые под–деревья соответственно. У этих функций два аргумента: дерево выражений и приоритет оператора в корне дерева, основываясь на значении последнего мы решим нужны–ли скобки в выражении или нет. Чтобы учитывать ассоциативность операторов мы различаем левое под–дерево от правого. Если приоритет текущего оператора одинаков с корневым, то ставить скобки для левого под–дерева не нужно. Для правого под–дерева скобки могут понадобиться, как в следующих случаях: 1-(2-3) or 1-(2+3).
Начальное дерево рассматривается как левое под–дерево оператора с минимальным приоритетом (0). Вот как работает функция вывода выражений pp_expression:
Для вывода инструкций, воспользуемся предыдущей функцией. При этом добавим номер перед каждой инструкцией.
Синтаксический и лексический анализ реализуют противоположную выводу на экран операцию. Для полученной строки создается синтаксическое дерево. Лексический анализ разбивает строку инструкции на независимые лексические части, называемые лексемами. Для этого добавим следующий тип в Objective CAML:
Для обозначения конца выражения мы добавили специальную лексему Lend. Она не является частью анализируемой строки, а добавляется функцией лексического анализа (см. стр. ??).
Для анализа строки мы используем тип запись содержащую изменяемое поле, значение которого указывает на часть строки, которую осталось обработать. Размер строки будет необходим во многих случаях, поэтому мы храним это константное значение в записи.
Такой способ определения лексического анализа можно рассматривать как применение функции к значению с типом string_lexer, в результате чего получим значение типа lexeme. Изменение индекса строки, которую осталось проанализировать, получается в результате побочного эффекта.
Следующие функции извлекают лексему из строки и изменяют маркер текущей позиции. Функции extract_int и extract_ident извлекают целое число и идентификатор соответственно.
Функция lexer использует обе предыдущие функции для извлечения лексем.
Принцип действия функции lexer очень простой: здесь анализируется текущий символ строки, в зависимости от его значения возвращается соответствующая лексема и текущая позиция перемещается на начало следующей лексемы. Это очень простой и эффективный подход, две лексемы могут различаться по первому же символу. Для символа `<' необходимо проверить следующий символ, за ним может следовать `=' или `>' и является другой лексемой. То же самое касается символа `>'.
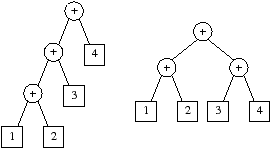
При анализе выражений языка возникают некоторые проблемы; знание начала выражения не достаточно для того, чтобы определить всю его структуру. Пусть мы анализируем часть строки 1+2+3. В зависимости от того, что за этим следует +4 или *4, полученные деревья для части 1+2+3 различаются (см. рис. 5.2).
Однако, структура дерева для 1+2 одинакова в обоих случаях, поэтому мы можем его построить. В связи с тем что у нас отсутствует информация о части +3, мы временно сохраним это информацию до нужного момента.
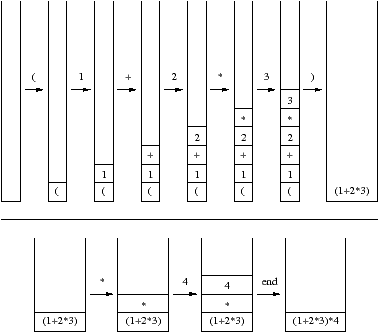
При построении дерева абстрактного синтаксиса мы воспользуемся стековым автоматом, схожий с тем, который используется yacc (см. стр. ??). Лексему читаются одна за другой и помещаются в стек до тех пор, пока у нас не будет достаточно информации, чтобы построить выражение. После этого, лексемы удаляются из стека и заменяются построенным выражением. Эта операция называется редукцией.
Тип помещаемых в стек элементов следующий:
Заметим, что правые скобки не сохраняются, так как лишь левые скобки важны при операции редукции.
На рисунке 5.3 проиллюстрировано изменение стека при анализе выражения (1+2*3)*4. Символ над стрелкой есть текущий символ строки.
Определим исключение для синтаксических ошибок.
Сначала определим операторы при помощи символов.
Функция reduce реализует редукцию стека. Существует два случая, в которых стек начинается:
Кроме того, другой аргумент функции reduce — это минимальный приоритет, который должен иметь оператор, чтобы редукция имела место. Для приведения без условий достаточно указать минимальный нулевой приоритет.
Заметим, что элементы выражения помещаются в стек в порядке чтения, из–за чего необходимо поменять местами операнды бинарной операции.
stack_or_reduce это главная функция синтаксического анализа, в соответствии с переданной ей лексемой она либо помещает новый элемент в стек либо выполняет редукцию.
После того как все лексемы извлечены и помещены в стек, дерево абстрактного синтаксиса может быть построено из элементов оставшихся в стеке — это задача функции reduce_all. Если анализируемое выражение было правильно сформировано, то в стеке должен остаться лишь один элемент, содержащий дерево этого выражения.
Основной функцией анализа выражений является parse_exp. Она просматривает строку, извлекает различные лексемы и передает их функции stack_or_reduce. Анализ прекращается, когда текущая лексема соответствует предикату переданному в аргументе.
Заметим, что лексема, которая определяет конец анализа, не используется при построении выражения. Для того чтобы проанализировать эту лексему позднее, необходимо установить текущую позицию на ее начало (переменная p).
Перейдем теперь к анализу строки с инструкцией.
И наконец, главная функция синтаксического анализа команд введенных пользователем в интерактивном цикле.
Программа на Basic состоит из набора строк и выполнение начинается с первой строки. Интерпретация строки программы заключается в исполнении задачи инструкции, которая находится на этой строке. Существует три множества инструкций: ввод/вывод (PRINT и INPUT), декларация переменных или присвоение (LET) и переход (GOTO и THEN). Инструкции ввода/вывода реализуют взаимодействие с пользователем, для этого будут использованы соответствующие команды Objective CAML.
Для объявления и присвоения переменных, необходимо уметь вычислить значение арифметического выражение и знать расположение в памяти этой переменной. Результат вычисление выражения может быть либо целым числом, либо булевым значением, либо строкой. Сгруппируем их в типе value.
При объявлении переменной, нужно выделить память, чтобы хранить значение ассоциированное этой переменной. Для изменении переменной необходимо поменять значение связанно с именем переменной. Соответственно, программа Basic использует окружение, которое хранит связки имя переменной–значение. Данное окружение представлено в виде списка из пар (имя, значение).
Для того чтобы получить содержимое переменной мы используем ее имя. При изменении значения переменной, меняется соответствующая пара.
В инструкциях перехода, условного или безусловного, указывается номер строки на которой должно продолжится выполнение программы. По умолчанию — это следующая строка. В связи с этим, необходимо запомнить номер текущей строки.
Список инструкций из которых состоит программа, редактируемая в интерактивном цикле, не подходит для эффективного выполнения программы. Действительно, для того чтобы реализовать переход (If и Goto) необходимо пересмотреть весь список инструкций, чтобы найти строку с нужным номером. Для того чтобы можно было напрямую перейти на нужную строку, достаточно заменить структуру списка на вектор. В данном случае при переходе будет использоваться не номер строки, а ее индекс в векторе. В этом случае, перед запуском программы командой RUN, проделаем пре–обработку инструкций, называемую компоновкой (assembly). По некоторым причинам, которые будут объяснены в следующем параграфе, скомпонованная программа представлена вектором строк, а не инструкций.
Как и для калькулятора из прошлых глав, вычислитель использует состояние, которое изменяется при каждом вычислении. Информация, которую необходимо знать в каждый момент — это программа в целом, следующая строка на выполнение и значения переменных. Выполняемая программа отличается от программы набранной в интерактивном цикле. Вместо того списка инструкций, мы используем вектор инструкций. Таким образом состояние программы описывается следующим типом.
Ошибки могут возникнуть в двух следующих случаях: вычисление выражения и переход на несуществующую строку. Соответственно, нужно обработать эти оба случая, чтобы интерпретатор корректно останавливался и выводил сообщение об ошибке. Определим исключение, а также функцию, которая будет его возбуждать и указывать номер строки на которой оно произошло.
Компоновка программы, состоящей из списка нумерованных строк (тип program), заключается в переводе списка в вектор и корректировки инструкций перехода. Эта корректировка реализуется связкой номера строки и соответствующего ей индекса вектора. Для облегчения задачи, мы создаем вектор нумерованных строки. Данный вектор будет просматриваться каждый раз, когда необходимо найти индекс связанный со строкой. Если номер строки не найден, будет возвращено значение -1.
Функция вычисления выражений обходит дерево абстрактного синтаксиса и выполняет операции, указанные в каждом узле дерева.
В следующих случаях возбуждается исключение RunError: несоответствие типов, деление на ноль и необъявленная переменная.
Для того, чтобы реализовать вычисление строки инструкций, нам понадобятся несколько дополнительных функций.
Добавление новой связки (имя переменной–значение) в окружение, заменяет старую, с таким же именем, если она существует.
Другая функция, для вывода целых чисел или строк, пригодится при вычислении команды PRINT.
Вычисление инструкции есть переход из одного состояния в другое. В частности, окружение будет изменено, если инструкция это присвоение. Значение следующей строки на выполнение изменяется каждый раз. Если строка не существует, вернем значение -1.
При каждом вызове функция перехода из одного состояние в другое eval_cmd ищет текущую строку, выполняет ее и затем устанавливает номер следующей строки как текущую строку. Если мы достигли последней строки программы, то номеру текущей строки присваивается значение -1, что позволит нам остановить программу.
Будет рекурсивно применять функцию перехода, до тех пор, пока не получим состояние, в котором номер текущей строки равен -1.
Осталось лишь реализовать мини–редактор и собрать воедино все части программы, реализованные ранее.
Функция insert вставляет новую строку в соответствующее место в программе.
Функция print_prog выводит на экран код программы.
Функция one_command либо добавляет строку, либо выполняет команду. Она управляет состоянием интерактивного цикла, состоящего из программы и окружения. Это состояние, представленное типом loop_state, отличается от состояние выполнения программы.
Главной функцией является go, она запускает интерактивный цикл Basic.
Цикл реализуется локальной функцией loop. Цикл заканчивается при возбуждении исключения End функцией one_command.
Вернемся к игре C+/C-, описанной в главе 2 на странице ??. Вот ее эквивалент, написанный на Basic.
Пример запуска данной программы.
> RUN Give the hidden number: 64 Give a number: 88 C- Give a number: 44 C+ Give a number: 64 CONGRATULATIONS
Данный интерпретатор Basic обладает минимумом возможностей. Тем, кто желает его обогатить, мы предлагаем следующие расширения:
Напомним вкратце правила игры: необходимо исследовать минное поле, не попав при этом ни на одну из них. Минное поле — это двумерный массив, несколько элементов которого содержат скрытые мины, а остальные пусты. В начале игры, клетки поля закрыты и игрок должен их исследовать одну за одной. Игрок побеждает, если он исследовал все клетки поля, не содержащие мин.
На каждом этапе игры игрок может либо “открыть” клетку либо пометить ее как “заминированной”. Если он открыл клетку с миной, то игрок проигрывает. Иначе клетка меняет свой вид и в ней выводится число заминированных клеток вокруг (максимум 8). Если игрок пометил клетку как заминированную, то он не может ее открыть, не убрав метку.
Разделим реализацию программы на три части.
В этой части мы рассмотрим минное поле как абстрактную сущность, не уделяя внимания способам вывода на экран.
Минное поле характеризуется своими размерами и числом заминированных клеток. Сгруппируем эти три параметра в одной записи и определим конфигурацию по умолчанию: размер 10x10 и 15 мин.
Вполне естественно будет определить минное поле как двумерный массив. Так же нужно уточнить натуру элементов массива и информацию, которую необходимо знать для каждого из них. Состояние клетки может быть:
Последняя информация не так важна, это значение можно вычислить в нужный момент. Но будет проще сделать данный расчет раз и навсегда в начале игры.
Клетка представлена записью с четырьмя полями, хранящими вышеуказанную информацию.
Двумерный массив есть вектор векторов клеток.
Далее в программе нам понадобится применять функцию к каждой клетке поля. Реализуем универсальный итератор iter_cells, который применяет указанную функцию f к каждому элементу массива конфигурации cf.
Здесь мы получили хорошее сочетание функционального и императивного стилей. Для итеративного применения функции с побочным эффектом (она не возвращает результат) ко всем элементам массива, используется функция высшего порядка (функция, аргумент которой есть другая функция).
Расположение заминированных клеток будет определяться случайно. Для r и c, число линий и колонок заминированного поля, и m число мин, необходимо получить список состоящий из m чисел в интервале от 1 до r*c. В алгоритме подразумевается, что m<r*c, однако необходимо сделать эту проверку в программе.
Простым решением этой задачи будет создание пустого списка. Затем мы генерируем случайное число и размещаем его в список, если оно уже не принадлежит списку. Повторим эту операцию до тех пор, пока в списке не будет m чисел. Для этих целей, воспользуемся следующими функциями из модулей Random и Sys:
Модули, содержащие эти функции, описаны в главе 7 на страницах ?? и ?? соответственно.
У функции, случайно выбирающей заминированные клетки, два аргумента: общее число клеток (cr) и число мин(m). Она возвращает список из m линейных координат.
Мы не можем заявить что эта функция, так она написана, закончится через определенное число итераций. Если генератор случайных чисел достаточно хороший, то можно лишь с уверенностью сказать, что вероятность того что эта функция не закончится равна нулю. Откуда мы получаем парадоксальное суждение: <<функция закончится если она выполняется бесконечно>>. Однако, на практике эта функция никогда нас не подводила, поэтому удовольствуемся данным негарантированным определением для генерации списка заминированных клеток.
Для того, чтобы при каждой новой игре получить разные заминированные клетки, нужно инициализировать генератор случайных чисел. Инициализировать будем при помощи процессорного времени в миллисекундах, которое истекло с момента запуска программы.
Практика показывает, что одна и та же программа затрачивает в среднем одинаковое время, из–за чего мы получаем схожий результат функции generate_seed. В связи с этим, функция Unix.time предпочтительней (см. гл. 17).
Во время инициализации минного поля, а так же в ходе игры, необходимо знать для данной клетки число окружающих заминированных клеток (функция neighbors). При вычислении множества соседних клеток, мы учитываем крайние клетки, у которых меньше соседей, чем у тех что находятся в середине поля (функция valid).
Инициализация минного поля реализуется функцией initialize_board, она выполняет четыре задачи:
В этой функции используется несколько локальных функций, которые мы вкратце опишем.
Если во время игры игрок открывает клетку у которой нет ни одного заминированного соседа, он с уверенностью может открыть соседние клетки, до тех пор пока есть такие клетки. Для того, чтобы избавить игрока от этой нудного момента игры, не требующего размышления, игра сама откроет нужные клетки в этом случае. При открытии клетки функция cells_to_see возвращает список клеток которые можно открыть.
Идея алгоритма достаточно просто излагается: если у открытой клетки есть заминированные соседи, то список ограничивается лишь этой самой клеткой, иначе список состоит из ее соседей, а так же из соседей ее соседей. Трудность состоит в том, чтобы написать незацикливающуюся программу, так как клетка является соседом самой себе. Надо избежать проверки по несколько раз одной и той же клетки поля. Для того, чтобы знать какая клетка была открыта, создадим вектор visited булевых значений. Размер вектора соответствует количеству клеток. Если элемент вектора равен true, это значит что соответствующая клетка была исследована. Рекурсивный поиск клеток осуществляется только среди непомеченных клеток.
Используя список соседних клеток, функция relevant, вычисляет два под–списка. Каждый под–список состоит из незаминированных, неоткрытых, непомеченных игроком и непроверенных клеток (которым соответствует значение false в векторе visited, прим. пер.). Первый под–список включает соседей, у которых есть как минимум один заминированных сосед, второй состоит из соседних клеток без заминированных соседей. Эти клетки помечаются как проверенные. Заметим, что помеченные игроком клетки, даже если они на самом деле незаминированы, исключаются из списков. Смысл метки заключается как раз в том, чтобы избежать открытия клетки.
Функция cells_to_see_rec рекурсивно реализует цикл поиска. Исходя из обновляемого списка клеток, которые необходимо проверить, она возвращает список клеток, которые будут открыты. Начальный список содержит лишь последнюю открытую клетку, которая помечена как проверенная.
С первого взгляда, аргумент cells_to_see_rec увеличивается между двумя последовательными вызовами функции, тогда как рекуррентное отношение основывается на этом аргументе. Соответственно, может возникнуть вопрос — заканчивается ли эта функция? Использование вектора visited гарантирует, что уже проверенная клетка не будет включена в результат relevant. В то же время, клетки, которые добавляются в список проверяемых клеток, происходят из relevant. Этим гарантируется, что определенная клетка будет возвращена relevant всего один раз и в следствии она будет представлена в единственном экземпляре в списке проверяемых клеток. Раз количество клеток ограничено, значит наша функция тоже закончится.
На этом неграфическая часть игры заканчивается. Рассмотрим стиль программирования, которым мы воспользовались. Выбор изменяемых структур данных вынуждает использовать императивный стиль с циклами и присвоением. Однако, для решения дополнительных задач мы применили списки и функции обработки в функциональном стиле. Стиль программирования предписывается структурами данных, которыми мы манипулируем. Функция cells_to_see тому хороший пример: она использует списки и, вполне естественно, эта функция написана в функциональном стиле. Для хранения информации о проверенных клетках мы используем вектор, обновление вектора осуществляется императивно. Конечно, мы могли бы сделать тоже самое в чисто функциональном стиле, используя список. Однако, цена этого решения выше, чем для предыдущего (поиск элемента в списке напрямую зависит от размера списка, тогда как для вектора время поиск есть константная величина) и оно не является более простым.
Эта часть игры зависит от структур данных, которые представляют состояние игры (см. стр. ??). Цель этой части — изобразить на экране различные компоненты игры, как на рисунке 5.5. Для этого воспользуемся функциями рисования блоков, описанными ранее на стр. ??.
Свойства различных компонентов игры описываются следующими параметрами.
При помощи этих параметров мы расширим базовую конфигурацию игры (значения с типом config) и определим новую запись window_config. В поле cf содержится минимальная конфигурация. Каждой компоненте, изображенной на экране, ассоциируем блок: основное окно (поле main_box), минное поле (поле field_box), диалоговое окно (поле dialog_box) из двух блоков (поля d1_box и d2_box), кнопка для пометки (поле flag_box) и текущая клетка (поле current_box).
Кроме этого, значение с типом window_config содержит две функции:
Определим функцию, которая создает графическую конфигурацию (с типом window_config) в соответствии с минимальной конфигурацией (с типом config) и вышеописанных параметров. Значения параметров некоторых компонент зависят друг от друга. Например, ширина основного блока зависит от ширины блока минного поля, которых в свою очередь зависит от количества столбцов. Чтобы не вычислять одно и то же по несколько раз, мы будем постепенно инициализировать эти поля. В отсутствии специальных функций данный этап инициализации немного нудный.
Теперь нам предстоит определить функции вывода клеток в различных случаях: клетка может быть открыта или закрыта, содержать или нет информацию. Вывод (блока) текущей клетки всегда будет осуществляться (поле cc_bcf).
Определим две функции изменяющие конфигурацию текущей клетки; одна закрывает клетку, другая открывает ее.
В зависимости от ситуации, необходимо выводить информацию на клетках. Для каждого случая мы определяем функцию.
Вывод закрытой клетки:
Вывести открытую клетку с числом мин:
Вывод клетки, содержащей мину:
Вывод заминированной и помеченной клетки:
Вывод ошибочно помеченной клетки:
В ходе игры, выбор соответствующей функции вывода клетки осуществляется следующим:
Для вывода клеток в конце игры, воспользуемся специальной функцией. Она немного отличается от предыдущих тем, что к концу все клетки должны быть открыты. К тому же, на ошибочно помеченных клетках выводится красный крест.
Состояние режима отметки клеток отображается выпуклым или вогнутым блоком с надписью ON или OFF:
Выведем надпись о предназначении помечающей кнопки.
На протяжении всей игры число клеток, которые осталось открыть и число помеченных клеток выводится в диалоговом окне с обеих сторон помечающей кнопки.
Чтобы нарисовать начальное минное поле, нужно вывести (число линий)×(число столбцов) раз закрытую клетку. Хоть это и один и тот же рисунок каждый раз необходимо нарисовать и заполнить прямоугольный и четыре трапеции, на это может уйти немало времени. Для ускорения этого процесса, воспользуемся следующей техникой: нарисуем один раз клетку, захватим ее в виде растрового изображения (bitmap) и затем скопируем эту кнопку в нужных местах.
В конце игры, все минное поле открывается и на неправильно помеченных клетках ставится красный крест.
И наконец, основная функция вывода на экран открывает графический контекст и выводит начальное состояние различных компонент.
Заметим, что все графические функции используют конфигурацию с типом window_config. Это делает их независимыми от расположения компонент игры. Если мы пожелаем изменить это расположение, код функций останется неизменным, необходимо будет лишь обновить конфигурацию.
Определим возможные действия игрока:
Напомним, что событие Graphics должно быть связанно с записью (Graphics.status), в которой хранится информация о текущем состоянии клавиатуры и мыши в момент возникновения события. Все события мыши, кроме нажатия на кнопку пометки или на клетку минного поля, игнорируются. Чтобы различать оба события, создадим соответствующий тип.
Действия нажатия и отпускания кнопки мыши соответствуют двум разным событиям. Если оба события произошли на одной и той же компоненте (клетка минного поля или кнопка пометки), то такой клик считается правильным о обрабатывается.
Сердце программы находится в функции loop и заключается в ожидании и обработке событий. Эта функция похожа на skel, описанной на странице ??, однако здесь мы точнее определяем тип события мыши. Условия остановки цикла следующие:
Объединим данные, необходимые функциям обрабатывающим взаимодействие с игроком, в записи minesw_cf.
Эти поля соответствуют:
Теперь мы готовы, к тому чтобы написать основной цикл.
Функции инициализации, окончания и обработки клавиатуры достаточно банальны.
Для обработки событий мыши нам понадобится несколько дополнительных функций.
Функция, обрабатывающая события мыши, сопоставляет значение типа clickon.
При создании конфигурации игры, нам необходимо три параметра: число линий, число колонок и число мин.
Функция, запускающая игру, сначала создает конфигурацию игры с помощью трех выше указанных параметров и запускает цикл обработки событий.
Вызов go 10 10 10 запускает игру, показную на изображении 5.4.
Из данной программы можно сделать самостоятельный исполняемый файл. В главе 6 объяснено как это сделать. После этого, можно сделать игру более удобной, передавая размер минного поля в командной строке. Передача аргументов рассматривается в главе 7, где приводится пример для данной игры (см. стр. ??).
Другое интересное расширение — научить машину саму открывать клетки. Для этого необходимо уметь определять следующий правильный ход и играть его первым в этом случае. Затем вычислить вероятность присутствия мины для каждой клетки и играть клетку, для которой это значение минимально.